Histoire d’Œ, histoire d’@
des rumeurs
typographiques et
de leurs enseignements
Résumé
Cette note est la première version-brouillon correspondant à un exposé fait lors du colloque Didapro'2003 sur la didactique des progiciels de traitement de textes. On montre que beaucoup d'affirmations typographiques erronées courent dans le monde de la PAO. On en démonte quelques-unes et on essaye d'expliquer l'origine de ces erreurs, le remède étant bien sûr une formation de qualité qui montre les choses cachées par les outils de la PAO.
Mots clés : Traitement de texte, caractères, règles typographiques, rumeurs, erreurs.
Introduction
Parmi les lacunes de l'enseignement secondaire, la méconnaissance de la typographie par les bacheliers a toujours passé inaperçue puisque cette discipline restait l'apanage de professionnels dont on peut même dire qu'ils gardaient leur savoir de façon très jalouse. Mais depuis que tout un chacun peut utiliser les systèmes de traitement de texte, voire des outils très professionnels de composition, il faut bien avouer que le savoir des typographes n'est pas passé dans le grand public à tel point d'ailleurs que le public justement ne s'en rend pas compte, persuadé que ce qu'il fait est bien, « d'ailleurs j'ai copié ce que j'ai vu… »
Il est donc heureux que commencent à paraître divers manuels d'initiation à la typographie dont celui de Perrousseaux[1] qui a une attitude très généreuse : « Soyons très tolérants. Puisque les auteurs n'ont pas eu de formation, ils ne peuvent pas savoir ce qu'il convient de faire et c'est à nous, professionnels, de les en informer. » Toutefois cette volonté d'éduquer ne suffit pas à supprimer certaines « affirmations » (parfois contradictoires, par exemple « on n'accentue pas les majuscules » et son contraire « Les typographes ont toujours accentué toutes les majuscules »), affirmations qui traînent sur le web, qui sont parfois publiées sans vérifications dans des livres, voire qui, plus grave, influencent des instances de normalisation qui prennent alors des décisions erronées qui mettent du temps à être corrigées (comme la disparition du œ dans le codage Latin-1).
Nous proposons ici de montrer quelques-unes de ces erreurs trop répandues en nous limitant toutefois à un niveau très bas des traitements de textes, celui des caractères. Nous essayerons de dépasser le simple bêtisier et de montrer que ces erreurs ont souvent un fondement et qu'il n'y a pas en typographie de règles formelles.
Normes, standards et ISO
La distinction entre norme et standard est plutôt française, mais si les anglo-saxons n'utilisent que le mot standard, ils qualifient souvent de proprietary standard ce que nous appelons standard en français [2].
Les normes sont le fait d'organismes nationaux ou internationaux, dont le plus important,les regroupant tous en quelque sorte, est l'ISO [3]. Hélas, si ce que nous venons de mettre en note concernant le sigle ISO apparaît dans de très nombreux livres, thèses, articles, etc., c'est faux !
En effet ISO n'est pas un sigle mais le « nom court » de l'organisation internationale de normalisation qui a trois noms officiels : « Organisation internationale de normalisation », International Organization for Standardization et Международн ая органиэац ия по стандар тиэации. On lit en effet sur le site de l'ISO [4] :« Because "International Organization for Standardization" would have different abbreviations in different languages ("IOS" in English, "OIN" in French for Organisation internationale de normalisation), it was decided at the outset to use a word derived from the Greek isos, meaning "equal". Therefore, whatever the country, whatever the language, the short form of the organization's name is always ISO. » et aussi [5] : « Parce que le nom de l'Organisation internationale de normalisation donnerait lieu à des abréviations différentes selon les langues ("IOS" en anglais et "OIN" en français), il a été décidé d'emblée d'adopter un mot dérivé du grec isos, signifiant "égal". La forme abrégée du nom de l'organisation est par conséquent toujours ISO. ».
Cette erreur est fréquente mais très excusable : cette explication sent le a posteriori et l'on est de plus en plus entouré de sigles anglo-saxons (NATO, UN, WWW, etc.) même s'il existe des sigles équivalents en français. En fait ce que nous reprochons aux auteurs mettant ainsi cette note erronée en bas de page, c'est qu'ils n'aient pas pris la peine de vérifier, se contentant de copier ce qu'ils ont vu ailleurs, propageant ainsi un peu plus la faute. Mais cette erreur montre aussi cette tendance qu'ont certains scientifiques français à croire que le français n'est pas une langue digne de la science internationale, et que ça fait plus sérieux d'écrire en anglais. Pour rester dans ce domaine de la normalisation des caractères, signalons que nous avons eu le plus grand mal à obtenir de tous les auteurs d'un numéro spécial d'une revue consacré au standard Unicode (André Hudrisier 2002) qu'ils emploient tous les abréviations et termes français (CJC, grandboutien, PMB…) et non ceux anglais (CJK, bigendian, BMP…) qui n'ont pas plus de valeur normative que ceux français et qu'il n'y a aucune raison de les conserver sous prétexte qu'ils sont passés dans les usages !
L'ASCII
L'ASCII [6] est en fait le nom d'une norme américaine (ayant eu divers noms) devenue norme internationale en 1983 sous le nom ISO 646. Disons en deux mots qu'il s'agit d'un codage en 7 moments (ou 7 bits) de caractères latins (majuscules et minuscules non accentuées et quelques signes de ponctuation et autres).
Ce terme ASCII est passé dans les usages et comme la différence avec ISO 646 est minime, on ne devrait pas s'en offusquer. En revanche, deux emplois de cette expression méritent d'être relevés car leur connotation cache une méconnaissance des normes de caractères.
- Pour beaucoup de gens, ASCII veut dire « texte brut » (non formaté) et ils n'hésitent pas à vous envoyer par courrier électronique (en précisant « je t'envoie ça en ASCII ») un texte contenant des lettres accentuées et autres symboles qu'on trouve dans des normes plus récentes (comme Latin-1) ou surtout dans des standards commerciaux comme ceux d'IBM ou de Microsoft.
- Souvent on entend « c'est en ASCII 8 bits », ce qui est impossible puisque ASCII est défini sur, et seulement sur, 7 bits. Ici encore, il y a confusion avec ces codages propriétaires.
Ces deux erreurs, voisines, viennent d'utilisateurs de PC [7] par le biais d'un formateur (Word, textedit, etc.) et qui ne font pas la différence entre texte source et texte formaté [8]. Ceci est d'ailleurs de plus en plus sensible depuis que les logiciels de courrier électronique « formatent » les messages. Il y a en effet trois choses différentes : a) le texte qu'on appelait autrefois « au kilomètre » ne comprenant que les lettres, chiffres, signes de ponctuation, etc. ; b) le même « enrichi » avec des commandes (SGML puis HTML et XML ont remis à la mode le terme de « balises », en anglais marks) de formatage (gras, justification, renfoncements, etc.) ou de structuration et c) l'image composée (celle affichée sur écran ou celle imprimée sur papier) de ce texte. Or en général [9] les systèmes de traitement de texte ne montrent que ce dernier aspect des textes. Ce ne serait finalement pas gênant que les utilisateurs ne sachent comment sont codés leurs textes si ces codages étaient normalisés ou plutôt si les produits commerciaux utilisaient les normes internationales et non leurs propres codages propriétaires (un utilisateur de Microsoft étant aujourd'hui sûr de détenir « la » vérité, qui n'est pas la même que celle d'Apple ni d'Unix !). Unicode essaye d'attirer l'attention sur ces différents types de textes et parle de texte source ou brut, de texte enrichi, etc. Mais la distinction est encore lente à être présente dans les esprits.
Histoire d'@
Le codage ASCII comprend les 26 lettres, les chiffres et divers signes. Parmi eux se trouve le caractère @ que l'on découvre depuis la démocratisation d'Internet (qui n'a été ouvert au grand public qu'en 1992) et dont il est devenu en quelque sorte le logo [10]. Cependant, son existence est bien plus ancienne mais si peu connue qu'on raconte beaucoup de sornettes sur ce signe [11] !
C'est Ray Tomlinson qui a inventé ce symbole en 1972
Il est probable [12] que ce soit effectivement un certain Ray Tomlinson qui, travaillant pour la société BBN sous-traitante du ministère américain de la défense (le DOD), ait le premier utilisé, en 1972, le symbole @ pour les adresses de ce qui allait devenir les emails. Mais il n'a pas inventé ce symbole. En effet, il était déjà présent dans les premières versions d'ASCII et dans des codages antérieurs. Tomlison n'a finalement fait que comme les informaticiens de l'époque : ayant besoin d'un signe inusuel, il a utilisé @ ce qui était d'autant plus évident qu'il se dit at (à) en américain !
Cette erreur de paternité est classique [13] et d'autant moins grave qu'elle n'est qu'une erreur de formulation (« C'est R.T. qui le premier a utilisé @ pour les adresses… et a ainsi fait découvrir, plus tard, ce symbole méconnu. » serait mieux !)
Le caractère @ s'appelle arrobas
Dans les pays francophones, le signe @ est désormais appelé sous le nom d'arrobas, arrobace, arrobase, etc. Deux erreurs :
- Pour la forme : si tel devait être le cas, le nom devrait être francisé comme il l'a été depuis des siècles : arrobe ou arobe.
 À droite : extrait du Dictionnaire étymologique de Albert Dauzat, 1938.
À droite : extrait du Dictionnaire étymologique de Albert Dauzat, 1938.
-
Puisque ce signe n'était pas connu, au fond pourquoi pas l'appeler
ainsi[14]
plutôt que, comme il l'a été vers 1970-1990, a-enroulé, arabesque,
escargot, etc. D'ailleurs, à l'étranger
[15],
il porte des noms parfois cocasses comme « queue
de singe » ou « pâtisserie ».
Le fait qu'il ait été appelé arrobas en France vient probablement
[16]
de ce qu'on trouve ce symbole de poids dans les spécimens de fonderies
(catalogues de caractères pour imprimeurs), parfois même avec leur nom
espagnol, comme dans ce spécimen de Deberny (vers 1920) qui d'ailleurs
indique justement que notre @ est italique :
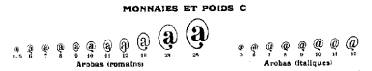
- Pour le fond, arobe est en effet le nom français de l'unité de poids espagnol arroba correspondant à ¼ de 100 livres (soit environ 12,5 kg) qui a été légalement en usage jusqu'il y a quelques années (et qui l'est encore, au moins de façon populaire, pour la vente des oranges).
-
Que cet @ ait représenté l'arobe, aucun doute ! En revanche il est aberrant
de prétendre que ce soit ce signe de poids espagnol qui est présent dans l'ASCII
(et l'on pourrait même dire qu'il s'agit alors d'un manque d'esprit critique…).
De nombreuses raisons à cela :
- Cette confusion n'existe qu'en France et en Espagne. Si le @ d'ASCII était le symbole pondéral espagnol, on en trouverait mention dans d'autres pays et notamment aux USA où cette unité semble méconnue.
- Lorsque l'ASCII a été défini, il y avait une série d'une dizaine de caractères à usage national, chaque pays pouvant y mettre ce qu'il voulait : L'AFNOR française a mis [17] ç à m § etc. ; les USA y ont mis # $ @ etc. : si les Espagnols tenaient à leur arroba, ils l'auraient mise, or il n'en a rien été.
- On pourrait se demander pourquoi dans un codage où il y a si peu de caractères (96 dont déjà 62 lettres et chiffres) on aurait mis le symbole d'une unité malgré tout peu utilisée dans le monde [18] !
- Enfin, ce n'est pas parce que deux symboles sont similaires qu'ils ont la même origine ! On a trouvé des signes ressemblant à @ chez des tisserands de la Mayenne au XVIIIe siècle, dans des armoiries et même sur la panse d'Ubu ; on l'a aussi assimilé à © ou… à la marque jaune de Mortimer ! Mais rien de tout ça ne peut avoir quelque rapport avec l'ASCII !
D'où vient alors ce signe @ ?
Ce signe @ ne peut être dissocié de & et #, qui sont deux autres signes utilisés en comptabilité américaine et pour le commerce. Tous trois sont présents dans ASCII car ils faisaient partie des premiers jeux de caractères d'ordinateurs (rappelons que le B d'IBM veut dire business) ; ils étaient déjà, avant 1940, dans les matériels de la mécanographie, auparavant sur les claviers des machines à écrire américaines, et même dans les spécimens d'imprimerie.
Ces trois figures montrent :
 des extraits d'une étude faite par l'ACM (Association for Computer Machinery) en 1960,
des extraits d'une étude faite par l'ACM (Association for Computer Machinery) en 1960,
 d'un catalogue de machine à écrire de 1921
d'un catalogue de machine à écrire de 1921
 et d'un spécimen de fonderie américaine de la fin du XIXe siècle.
et d'un spécimen de fonderie américaine de la fin du XIXe siècle.
Ces trois symboles ont donc en commun d'avoir été utilisés en comptabilité américaine [19] depuis au moins le XIXe siècle (mais depuis quand ?) et de correspondre à des abréviations latines. Il n'y a guère de doutes sur deux d'entre eux : « » est l'esperluette [20] qui vers 1900 ne servait plus guère qu'à nommer des sociétés commerciales (Dupont & Dupond) et « # » pour numerus. [21] Mais il faut bien avouer qu'@ est moins connu même si certains [22] pensent qu'il s'agit d'une déformation de la ligature latine a¶ (à, at en anglais) ce que laisse d'ailleurs penser son usage anglo-saxon (prix unitaires). Toutefois, il faut être extrêmement prudent car finalement il ne semble pas qu'il y ait d'attestations [23] de ce @ dans des documents anciens [24]. Et en tout cas il manque le maillon entre le Moyen-Âge et les comptables américains !
Le codage Latin-1
L'ASCII péchant par son très petit nombre de lettres, divers standards ont été proposés (EBCDIC d'IBM, VT200 de DEC, etc.) qui ont fini par déboucher sur la norme ISO 8859 qui est en fait un ensemble de 16 (aujourd'hui) codages où les langues sont regroupées par affinités commerciales et qui ont tous en commun d'être un sur-ensemble de l'ASCII et de coder les caractères sur 8 bits. Le plus répandu dans le monde occidental est ISO 8859-1 plus connu sous le nom de Latin-1. Qui, comme l'ASCII, véhicule plusieurs légendes !
On n'accentue pas les majuscules
Latin-1 offre un très grand nombre de lettres accentuées à é è ô ù (mais aussi ì ø ě å…) et les mêmes en majuscules (À É È Ô Ù… Ì Ø ě Å). On entend alors diverses remarques sur l'obligation ou la défense d'accentuer les majuscules. Un peu comme ceci[25]:
- On n'accentue pas les majuscules.
- Vous avez peut-être appris ceci à l'école primaire, mais ce n'est valable que pour les lettres manuscrites dont on n'accentue jamais les majuscules.
- C'est faux, Le Bé [26] écrivait son nom en majuscules anglaises accentuées. D'ailleurs les imprimeurs ont toujours accentué les majuscules.
- Faux. D'abord parce que les accents n'ont été en usage que deux siècles après l'invention de l'imprimerie. On trouve par ailleurs plein de livres des XVIIe et XVIIIe siècles sans majuscules accentuées.
- Oui, mais on trouve aussi des livres avec des majuscules accentuées par « bricolage » (par exemple en faisant suivre un E d'une apostrophe E' pour faire É) !
- N'empêche que la « casse parisienne », utilisée depuis deux siècles au moins, n'avait que trois majuscules accentuées (È É Ê).
- C'est oublier que les typos disposaient aussi d'un casseau où il y avait les caractères moins fréquents, comme À Ô, etc. D'ailleurs l'Imprimerie nationale[27] dit : « On veillera à utiliser systématiquement les capitales accentuées, y compris la préposition À ».
- Malgré son nom, l'Imprimerie nationale n'est pas, pour les règles typographiques, l'équivalent de l'Académie française pour l'orthographe. D'ailleurs, il n'y a pas de règles, pas de code au sens du Code Napoléon, mais seulement des « marches », des usages. Le journal Le Monde par exemple « n'accentue les majuscules que dans les parties de texte tout en majuscule [28] » faisant ainsi, comme les typographes romands (en Suisse), la distinction entre capitale (objet typographique utilisé par exemple dans les titres où « tout est en majuscule » comme dit Le Monde) et majuscule (objet linguistique, en début de phrase ou de nom propre par exemple).
- N'empêche que les capitales accentuées aident à lever des ambiguïtés comme « UN POLICIER TUE », « SABLES SALES » ou « LE PALAIS DES CONGRES ».
- Attention à ces exemples rabachés à tort car incorrects (tuer est transitif) ou parce que les langues sont naturellement ambiguës, les ambiguïtés étant levées par le contexte. On ne s'attend pas à trouver une criée en plein Paris. En revanche, il est exact que cette enseigne de restaurant [29] « LE CONGRES - FRUITS DE MER » laisse croire qu'il y a un S en trop à CONGRE alors qu'il manque l'accent grave de CONGRÈS. De même, l'absence de contexte d'un titre de pièce de théâtre comme « CLAUDE S'EST TUE » laisse au moins deux interprétations possibles. Mais on n'a pas besoin de cette explication pour réclamer l'accentuation des majuscules, il suffit de dire « Il n'y a aucune raison [30] de ne pas accentuer les majuscules ».
- Etc.
Ce genre de discussion cache en fait au moins trois aspects :
- En typographie, il est très rare que l'on puisse dire « il faut ». Il est beaucoup plus sage de dire « il vaut mieux » ou « les usages veulent que ». Beaucoup de ces règles d'usage ont en fait été élaborées pour des raisons techniques mais aussi esthétiques, relevant donc du non-rationnel. Les règles d'utilisation concurrente des guillemets et de la ponctuation choquent les informaticiens car « le parenthésage n'est pas balancé » : la logique (car il y en a une) n'est pas celle des grammaires formelles ! La difficulté est alors de distinguer ce qui est fronde ou méconnaissance (par exemple laisser rejeter en début de ligne suivante un point-virgule ou abréger « kilogrammes » par « Kgs » voire « deuxième » par « 2ième ») de ce qui peut relever d'un choix réfléchi et justifié (par exemple écrire « L'École Estienne » par interprétation de la règle d'unicité). Là, c'est aux enseignants de bien informer (voir le point 3 ci-dessous). Enfin, il faut bien admettre que les règles typographiques ne s'appliquent pas toujours bien au français d'aujourd'hui ; le « code typographique » est vieux, mais les essais de rénovation échouent les uns après les autres[31] .
- L'infaillibilité des maîtresses d'école est assez tenace et il sera intéressant de voir si la nouvelle génération des élèves issus des IUFM où ils auront pratiqué la PAO évoluera en ce qui concerne les usages typographiques. Il est à craindre toutefois que la confusion entre « typographie » et « usage de tel ou tel système de traitement de texte » n'arrange guère les choses [32].
- Ce cas des majuscules accentuées est typique du non-dit des systèmes commerciaux de traitement de texte. On ne trouve nulle part, du moins de façon évidente, ce qu'il faut taper pour obtenir ces majuscules accentuées. Sur le Mac, par exemple, si on trouve assez facilement comment accentuer un À ou un Ô, il est en revanche bien difficile de trouver comment obtenir É ! Quitte à être long (puisqu'il y a beaucoup de systèmes), tout support de cours de PAO devrait avoir ces tables, ou la façon de les trouver. Et renvoyer, pour les usages typographiques, aux ouvrages comme (Perrousseaux 1995).
L'histoire d'œ
Le codage Latin-1 avait une grossière erreur (corrigée depuis dans Latin-9) : les caractères Œ et œ n'y figuraient pas. Pourquoi ? Tout simplement parce que le représentant français avait la grippe le jour où Latin-1 a été voté. Faux bien sûr… D'ailleurs, un vote n'a lieu qu'après des mois, voire des années, de discussions dans les CT (Commissions techniques) ; voir (Hernandez 2003). L'histoire est malheureusement plus complexe [33] et montre plutôt le désintérêt des Français pour la normalisation (Marti 1990) et que les experts sont plus souvent des ingénieurs que de vrais spécialistes du domaine (en l'occurrence ici la typographie et la linguistique).
Ceci fait partie des légendes (basées souvent sur un fond de vrai, ici que le Français, non pas le responsable national mais un expert du CT, a été fautif). Il en existe de nombreuses autres, par exemple [34] l'origine de l'ordre QWERTY des claviers ou l'échec de la sonde écrasée sur Vénus à cause d'une erreur de programmation en Fortran, etc. Ce qui est curieux c'est que ces erreurs perdurent, que personne ne songe à vérifier les dires et qu'en général on ne sache plus bien distinguer les sources dignes de foi des autres, voire des cafés du commerce !
Ϋ n'est pas français
Non seulement Latin-1 n'offrait pas Œ et œ mais, alors qu'ÿ y est bien présent, Ϋ manquait[35] ou plus précisément la place qu'il aurait dû logiquement occuper[36] était affectée à ß, un expert ayant déclaré que « Ϋ n'est pas français ». Latin-9 et Unicode ont rétabli Ϋ mais à une place différente. Reste que cette idée est assez tenace et relève du problème plus général que, au fond, les Français ne savent pas quelles sont les lettres françaises[37] ! Ceci est encore accentué par le fait que les vendeurs de fontes utilisent souvent le texte suivant
« Portez ce vieux whisky au juge blond qui fume »
équivalent français du texte anglais The quick brown fox jumps over the lazy dog. Nouvelle erreur, car si ce dernier compte bien les 26 lettres de l'alphabet anglais[38] , il n'en est pas de même du texte français puisqu'il ne contient pas une seule diacritique ! Il faudrait pour cela utiliser le pangramme[39] suivant « Dès Noël où un zéphyr haï me vêt de glaçons würmiens, je dîne d'exquis rôtis de bœuf au kir à l'haÿ d'âge mûr &cætera » qui contient les quarante-deux lettres françaises [40]. C'est un bon exercice que de demander aux élèves de PAO de le mettre tout en majuscule pour voir s'ils dominent bien leur clavier !
Peut-on encore parler d'erreur ici ? Ce concept d'alphabet n'est finalement pas aussi simple et varie selon que l'on est linguiste, typographe ou fonctionnaire d'état civil ! L'erreur est de ne pas situer et d'être péremptoire !
Conclusion
Un certain nombre d'affirmations fausses traînent donc en typographie. Nous avons montré certaines d'entre elles concernant l'usage des caractères. Mais il y en a bien d'autres, notamment en matière de lisibilité (« on n'écrit pas du texte courant en italique », « les caractères sans sérifs sont moins lisibles que ceux avec empattements », « on a toujours mis une espace fine avant les signes doubles », etc.). Il est donc important de rappeler qu'il n'y a pas de « règles » typographiques, mais seulement des usages, ce qui ne veut pas dire non plus qu'on peut faire n'importe quoi et c'est là qu'est toute la difficulté d'apprentissage de la matière ! Ce qui est encore accentué par le fait que la typographie est tombée dans le domaine public, qu'on a appris à utiliser la PAO avant d'apprendre à regarder.
De telles erreurs ou légendes existent dans d'autres matières (par exemple l'origine du mot bug) et parfois (c'est à notre avis ici le cas au moins de la raison de l'absence de œ dans Latin-1), relèvent des rumeurs[41] qui sont bien connues pour être tenaces. C'est le devoir de l'éducation, traditionnelle ou didacticielle, non seulement de ne pas les propager mais de les prévenir.
Enfin, ces erreurs ne touchent que des points de détail, ou qui paraissent n'être que des points de détail. Mais nous avons vu plusieurs fois que cela cachait en fait un problème bien plus profond : les utilisateurs de la PAO n'ont qu'une vision externe d'un « texte », ne voient que les glyphes et non les caractères sous-jacents, ne voient que la mise en page et non la structuration cachée, etc. On est rarement bon musicien sans un minimum de solfège et sans connaissance des mécanismes de son instrument. C'est ce solfège de la typographie et la mécanique de la PAO qu'il faudrait d'abord aborder pour un enseignement de qualité.
[1] Voir (Perrousseaux 1995) et son article dans ces actes. Voir aussi James Felici, Le Manuel Complet de Typographie, PeachPit Press, Paris 2003, 320 pages ; isbn : 2-7440-8067-5 (Complet mais... très américain, notamment les exemples} et Damien Gautier, Typographie, guide pratique, Pyramyd ,seconde édition 2001, ISBN : 2-910565-16-5.
[2] « On a coutume, en effet, d'opposer les normes, documents validés par des instances officielles et qui, de ce fait même, offrent une certaine garantie de stabilité et de pérennité, aux standards, états de fait résultant de mécanismes économiques et traduisant souvent la domination d'un industriel ou d'un groupe d'industriels sur un marché. » (Hernandez et Joly, 2003).
[3] International Standard Organization
[5] Le français est une des langues officielles de l'ISO. Nous avons donné la première forme anglaise car elle comporte le nom anglais et, écrite en anglais, elle prouve qu'il ne s'agit pas que d'une défense franco-française du français !
[6] American Standard Code for Information Interchange. Voir (Marti 1990) et (André Hudrisier 2002, p. 13-49) sur son histoire et son contenu.
[7] Au sens de Personnal Computer, c'est-à-dire aussi bien Windows que Mac…
[8] Pas plus qu'il ne font la différence entre un texte et sa mise en page, entre le visuel et le conceptuel. Les systèmes WYSIWYG sont certes agréables à utiliser mais cachent le fond des choses !
[9] Ce n'est pas vrai avec des « formateurs » comme LaTeX à qui on dit comment faire les choses et non en montrant ce qu'on veut. Certains éditeurs de HTML procèdent également de cette façon, l'utilisateur ayant alors à écrire les balises comme <H1> ou des entités comme
[10] Il suffit pour s'en convaincre de regarder son usage en publicité ou dans les médias, où @ remplace souvent un a pour donner une connotation internaute, où on note la qualité des CD et autres DVD par @, @@, @@@ comme on notait autrefois par *, ** ou *** (voire ƒ,ƒƒ,ƒƒƒ), etc.
[11] De nombreuses pages du web lui sont consacrées. On trouvera l'essentiel dans http://www.langue-fr.net/index/A/arrobe.htm.
[12] Voir à ce sujet Alain Le Diberder, Histoire d'@, l'abécédaire du cyber, La Découverte, Paris, 2000 (p. 20).
[13] On attribue à Scott Fahlman l'invention des smileys en 1981 (IEEE Annals of the History of Computing, vol. 25, no 3, sept. 2003, p. 82-83.) alors qu'on en trouve l'équivalent avec des caractères en plomb au début du XXe siècle (Lettre Gutenberg, 12, 1995).
[14] Le fait de donner un nom aux caractères est par ailleurs nouveau mais devient une nécessité avec les codages qui sont justement basés sur les noms, comme Unicode !
[15] Diverses pages du web sont consacrées à ces noms. En voici une : http://www.herodios.com/herron_tc/atsign.html
[16] On trouve souvent sur le web une autre explication (d'origine canadienne semble-t-il) : « Arrobas vient d'une déformation de l'appellation a rond bas de casse (c'est-à-dire a minuscule) utilisée par des typographes ». Aucune attestation sérieuse de ceci n'a été signalée !
[17] Et c'est devenu la norme avec ISO 646.
[18] On peut d'ailleurs faire la même remarque à propos du symbole # que France Télécom (notamment) appelle dièse : on ne voit pas bien ce que ce symbole musical ferait dans ce codage ASCII (et qui plus est sans ses homologues bémol et bécarre). D'ailleurs # ¹ ♯ ! Voir ci-après.
[19] En Angleterre, le caractère @ était encore utilisé sur les marchés vers 1970 mais le caractère # ne semble pas y avoir été utilisé. En France et en Allemagne, les caractères @ et # ne semblent pas connus chez les comptables !
[20] Il s'agit de la ligature « et » dont on connaît de nombreuses attestations depuis le Moyen Âge. Voir Gérard Blanchard, « Nœuds et esperluettes, actualités et pérenntié d'un signe » , Cahier Gutenberg 22, p. 43-61, 1995.
[21] Il s'agit en fait d'une abréviation latine de numerus (numéro) que l'on retrouve en comptabilité américaine (number) pour indiquer les numéros de série des pièces ou des comptes bancaires. Lui aussi semble attesté.
[22] Une des première mentions françaises de ceci est sans doute dans Jacques André et Adolf Wild, Ligatures, typographie et informatique, Rapport de recherche INRIA no 2429, décembre 1994. Je m'étais notamment basé sur des courriers de Charles Bigelow (typographe américain qui a par ailleurs repris ceci dans la liste comp.fonts) qui lui se basait notamment sur B. L. Ullman, Ancient writing and its influence, Cooper Square publ., New York 1963.
[23] Cette absence d'attestations n'est pas spécifique à ce caractère. Citons les légendes sur l'origine du signe dollar. Si l'on connaissait bien celle de son nom - le mot dollar vient du nom populaire d'une monnaie mexicaine dolera (dont le vrai nom est peso) qui vient lui-même du bas allemand daler, nom d'une monnaie « européenne » de Charles Quint frappée dans la vallée (Thal en allemand) de Joachim - beaucoup d'hypothèses fallacieuses ont été faites sur son dessin (détroit de Gibraltar avec un drapeau flottant, U+S superposés (sic), pièce de 8 réales, etc.). Mais aucune n'était crédible faute de trace. Finalement, Florian Cajori (A history of mathematical notations, vol. 2, Open Court Press, 1929) a trouvé des manuscrits permettant d'affirmer que le signe $ n'était que la déformation de Ps, abréviation de pesos ! Mais les autres légendes, beaucoup plus belles, continuent à circuler…
[24] En tout cas, on ne trouve pas ce signe dans l'ouvrage de référence sur les ligatures latines : Adriano Cappelli, Lexicon abbreviaturarum - dizionario di abbreviature latine ed italiane, Editore Ulrico Hoepli, Milano. On ne le voit pas non plus dans les manuscrits médiévaux où ad a d'autres formes ni d'ailleurs dans les incunables ou textes imprimés. Peut-être dans des ouvrages comptables anciens ?
[25] On verra de nombreuses discussions de ce type dans les archives de la « liste typographie » à https://www.irisa.fr/wws/info/typographie.
[26] Membre d'une famille d'imprimeurs célèbres, Pierre Le Bé est surtout connu pour son ouvrage BÉLE PRÉRIE, 1601 (réédition par Tschichold en 1974).
[27] Imprimerie nationale, Lexique des règles typographiques en usage à l'Imprimerie nationale, Paris, 2002.
[28] Laurent Greilsamer, Le style du Monde, Le Monde, Paris 2000 (page 6)
[29] À Montparnasse ; photo à http://www.gutenberg.eu.org/publications/lettres/63-lettre1.html (page 14).
[30] Du moins aujourd'hui, car plusieurs raisons ont été avancées pour excuser l'absence de capitales accentuées dans des textes imprimés : fragilité des types (les accents débordant le caractère en plomb pouvaient se briser), absence d'accents sur la majorité des claviers de machine à écrire ou difficulté de composer les capitales accentuées (par exemple utilisation de plusieurs touches ou utilisation d'un casseau pour les Linotypes d'origine américaine, excuse encore valable en PAO !).
[31] Il faudrait beaucoup de conditions pour réussir : avoir l'aval de toute la profession des anciens imprimeurs et des nouveaux usagers de la PAO, et ce dans tous les pays francophones ; se débarrasser de règles aberrantes (trop pointues ou de puristes) ; distinguer les règles génériques de celles spécifiques ; offrir à la fois une version « de référence » et une version « didactique » ; s'adapter aux matériels d'aujourd'hui et prévoir (comme certains le font déjà) le choix entre des règles de qualité et des règles de substitution (certains tolèrent pas exemple que l'on abrège « numéro » par « No », avec un o en exposant (au lieu d'un o supérieur que je suis incapable de composer ici avec Word : c'est un caractère qui a une graisse adaptée au corps courant, un peu comme celle des petites capitales qui est adaptée au corps courant, et plus grasses qu'une capitale réduite !) ou par « No », mais rejettent « N° » avec le symbole degré « ° » habituellement utilisé) ; etc.
[32] Lors de ce colloque de didactique, il a été mentionné des reproches faits à des enseignants qui avaient voulu donner des leçons sur l'usage typographique des ponctuations (qui n'est pourtant jamais enseigné dans les cours de français).
[33] Voir à ce sujet : http://www.gutenberg.eu.org/pub/GUTenberg/publicationsPDF/25-andre.pdf. En gros, dans les premières ébauches de l'alphabet Latin-1, les ligatures œ et Œ étaient bien présentes. Et pourtant, un des experts francophone a émis l'idée (fausse) que le caractère œ n'était qu'une convention typographique pour remplacer les lettres oe par œ tout comme on peut remplacer la succession des deux lettres f et i par la ligature fi !. L'expert français a appuyé cette idée... parce que les imprimantes fabriquées par la grande entreprise où il travaillait ne savaient pas imprimer œ ! La place réservée pour œ et Œ a alors été remplacée sous la pression d'Allemands par ÷ et ×.
[34] Nous laissons, pour tous ces exemples, le soin au lecteur de trouver la légende et sa vérité ! Le web permet heureusement de trouver souvent les deux versions ! Pour citer au moins un site : http://home.earthlink.net/~dcrehr/myths.html.
[35] Voir l'url citée à propos de Œ et œ.
[36] Latin-1, comme ASCII, était construit de façon que le code (en base 10) d'une majuscule était celui de la minuscule correspondante - 32. Ainsi code(a) = 97 et code(A) = 97-32 = 65 ; code(è) = 232, code(È) = 200 ; mais code(ÿ) = 255 et code(ß) = 223 !
[37] Il est presque choquant de voir l'Imprimerie nationale citer dans son lexique des règles typographiques le mot français malström alors qu'elle omet le ö dans la liste des voyelles accentuées françaises ! Et il s'en est fallu de peu que le ÿ ne passe encore à la trappe en juin 2003 lorsque les noms de domaine (pour écrire les adresses de courrier électronique) ont été étendus aux lettres accentuées minuscules et majuscules (permettant désormais d'écrire par exemple Pierre.LOUΫS@Université-La_Haÿe_les_Roses.fr).
[38] Ce que n'avait pas du voir l'éditeur de la version française d'un ouvrage d'informatique américain où STRING 'THE QUICK…DOG' a été traduit par CHAINE 'LE VIF RENARD BRUN SAUTE PAR DESSUS LE CHIEN PARESSEUX' !
[39] Texte minimal ayant un sens et utilisant toutes les lettres d'une langue. Voir Angelini, Mots en forme - bestiaire ébloui des lexies tératoïdes, Quintette, Paris 2001 (p. 114-117).
[40] On remarquera l'absence de ö et de ñ qui risquent d'être considérées comme françaises d'ici peu tandis que æ, utilisé quasi uniquement dans des noms scientifiques latins, risque de redevenir ae !
[41] Les sociologues s'intéressent beaucoup à ce phénomène, notamment aux rumeurs liées à l'Internet. On trouvera diverses écoles d'analyse dans trois ouvrages récents : Renard (J.-B.), Rumeurs et légendes urbaines, Que sais-je ? no 3445, PUF ; Campion-Vincent V. et Renard J.-B. (2002), De source sûre - nouvelles rumeurs d'aujourd'hui, Payot, ISBN : 2-228-89635-7 et Froissart P. (2003), La rumeur - histoire et fantasmes, Belin.
Bibliographie
André J. et Hudrisier H. (sous la direction de) (2002), « Unicode, écriture du monde ? », Document numérique, vol. 6, no 3-4, 364 p.
Hernandez J.-A. et Joly R. (2003), " Normalisation et standardisation dans les technologies de l'information et de la communication ", Techniques de l'ingénieur, H5018.
Marti B. et coauteurs (1990), Télématique - techniques, normes, services, Dunod.
Perrousseaux Y. (1995), Manuel de typographie française élémentaire, Atelier Perrouseaux éd.. Reillanne, ISBN : 2-911220-00-5.
Unicode Consortium (2000), The Unicode Standard, Version 3.0, Addison-Wesley, Reading. Pour une version à jour, voir : http://www.unicode.org/ et pour la version française : Andries P. (2003), Unicode 3.1 et ISO 10646 en français, http://Pages-infinite.net/hapax/.
Jacques ANDRÉIrisa/Inria-Rennes
Campus universitaire de Beaulieu
F-35042 Rennes cedex
Jacques.Andre@irisa.fr
Éditeurs : Bernard André
Georges-Louis Baron
Éric Bruillard
© INRP/GEDIAPS
Mis en ligne le 2 octobre 2003
Dernière mise à jour le 15 octobre 2003